목표 : 응용 프로그램의 비즈니스 로직을 외부 세계로부터 격리시켜 유연하고 테스트하기 쉬운 구조를 만드는 것
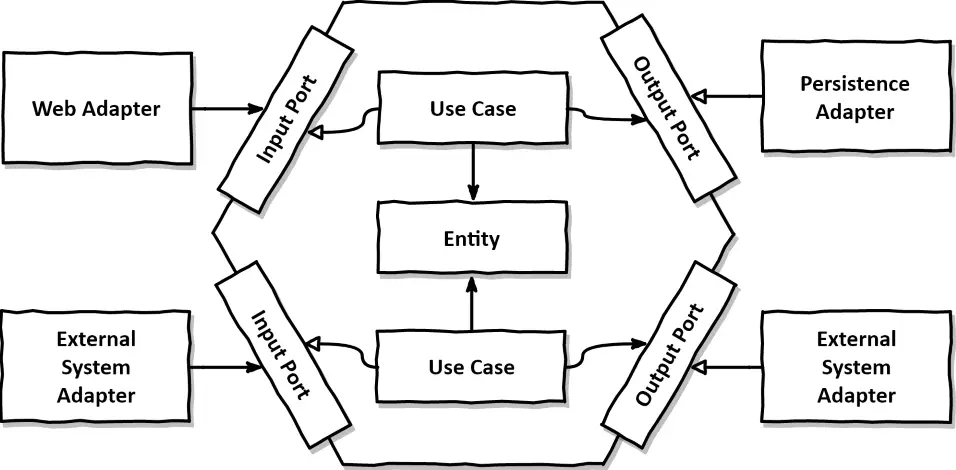
핵심 비즈니스 로직은 중앙의 도메인 영역에 위치하며, 입력과 출력을 처리하는 포트와 어댑터를 통해 외부와 소통한다.
헥사고날 아키텍쳐의 장단점
장점
유연성 : 외부 시스템이나 인프라와의 의존성을 낮추어, 구성 요소를 쉽게 교체하거나 업데이트 할 수 있다.
테스트 용이성 : 비즈니스 로직을 독립적으로 테스트할 수 있어 품질 향상과 개발 속도 향상에 도움이 된다.
유지보수성 : 책임이 분리되어 있어, 코드의 이해와 수정이 용이하며, 변화에 빠르게 대응할 수 있다.
단점
구현 복잡성 : 포트와 어댑터를 구성하고 관리하는데 약간의 복잡성이 따른다.
초반 개발 시간 증가 : 아키텍처를 처음 구축할 때 시간과 노력 필요
헥사고날 아키텍쳐 구조
포트 (인터페이스)
포트는 애플리케이션 코어의 경계를 정의하며, 애플리케이션 코어가 제공해야 할 기능을 나타내며 어댑터를 통해 애플리케이션 코어에 접근하는 인터페이스이다.
Input Port : 외부 요청이 애플리케이션 코어로 들어오는 경로를 정의한다. 예를 들어, 웹 요청, GUI 이벤트, 스케줄링 이벤트 등이 인커밍 포트를 통해 애플리케이션 코어로 들어올 수 있다.
Spring Web MVC의 Controller와 Service 사이의 인터페이스
Output Port : 애플리케이션 코어가 외부 세계에 서비스를 제공하기 위한 경로를 정의한다. 예를들어 데이터베이스, 메시징 시스템, 웹 서비스 등에 데이터를 전송하거나 요청하는 경우에 사용한다.
Spring web MVC의 Repository와 Service 사이의 인터페이스
어댑터 (구현체)
어댑터는 포트를 통해 애플리케이션 코어와 외부 세계를 연결한다. 어댑터는 특정 외부 기술이나 프레임워크에 의존적인 로직을 담당하며, 이를 통해 애플리케이션 코어는 외부와의 결합도를 최소화하고, 어댑터를 통한 교환 가능성을 확보한다.
Input Adapter : 사용자 인터페이스, 테스트 또는 외부 시스템으로부터의 요청을 애플리케이션 코어로 주도하는데 사용된다.
Spring Web MVC의 Controller
Output Adapter : 애플리케이션 코어에서 외부에 데이터를 전달하는 역할을 담당한다. 예를들어, 데이터베이스에 데이터를 저장하거나 외부 시스템에 메세지를 전송하는 등의 역할을 한다.
Spring Web MVC의 Repository
유즈케이스
Clean Architecture에서 사용하는 용어로 Spring Web MVC의 Service 영역에 해당한다.
헥사고날 아키텍쳐 예시
Kafka와 같은 외부 시스템과 연동하는 경우 헥사고날 아키텍쳐의 장점을 알 수 있다.
3계층 아키텍쳐에서 kafka 적용
// KafkaProducer.java
public class KafkaProducer {
public void send(User user) {
// 카프카에 사용자 정보 전송
}
}
// UserService.java
public class UserService {
private UserRepository userRepository;
private KafkaProducer kafkaProducer;
public UserService(UserRepository userRepository, KafkaProducer kafkaProducer) {
this.userRepository = userRepository;
this.kafkaProducer = kafkaProducer;
}
public void createUser(String name, String email) {
User user = new User(name, email);
userRepository.save(user);
kafkaProducer.send(user);
}
}
헥사고날 아키텍쳐에서 kafka 적용
// OutputPort.java
public interface OutputPort {
void sendMessage(User user);
}
// KafkaAdapter.java
public class KafkaAdapter implements OutputPort {
private KafkaProducer kafkaProducer;
public KafkaAdapter(KafkaProducer kafkaProducer) {
this.kafkaProducer = kafkaProducer;
}
public void sendMessage(User user) {
kafkaProducer.send(user);
}
}
// CreateUserUseCaseImpl.java
public class CreateUserUseCaseImpl implements CreateUserUseCase {
private UserRepository userRepository;
private OutputPort outputPort;
public CreateUserUseCaseImpl(UserRepository userRepository, OutputPort outputPort) {
this.userRepository = userRepository;
this.outputPort = outputPort;
}
public void createUser(String name, String email) {
User user = new User(name, email);
userRepository.save(user);
outputPort.sendMessage(user);
}
}
기존 아키텍쳐의 경우 UserService 클래스가 카프카와 직접 연결되어 있다. 이 경우 UserService는 Kafka에 대한 의존성을 가지게 된다.
반면 헥사고날 아키텍쳐에서는 OutputPort 인터페이스를 통해 외부 시스템과의 의존성을 분리한다.
이러한 구조를 통해 외부 시스템 변경이 있을 때에도 비즈니스 로직에 영향을 최소화 하고 유연성을 확보할 수 있다.
만약 메세지 서비스를 Kafka에서 RabbitMQ로 변경한다고 생각해보자.
기존 3계층 아키텍쳐의 경우 KafaProducer라는 클래스를 직접 의존하고 있기에, RabbitMQProducer라는 새로운 클래스를 생성하고 이를 사용하게 될 것이다.
하지만 핵사고날 아키텍쳐에서는 Output Port의 구현체를 KafkaAdapter 에서 새로 생성한 RabbitMQAdapter로 변경해주면 비즈니스 로직의 변화 없이 구현체만 바꾸는 것으로 빠르게 대응할 수 있을 것이다.
마무리
블로그 탐색중에 헥사고날 아키텍쳐라는 새로운 키워드를 발견하여 이에대해 간단히 조사해 보았다. 키워드를 발견했을때는 아키텍쳐에 깜짝 놀랄만한 변화가 있을 것 같았지만, 읽어보니 느낀점은 Spring 웹 서비스에서는 메세징 서비스와 같은 외부와 통신하는 부분을 한번 더 인터페이스로 감싸서 접근하는 방식으로 의존성을 줄인 것이라는 느낌이 든다.
아직 경험이 많이 부족하여 크게 와닿지 않는 것 같지만, 소스코드 탐색중에 Port, Adapter, UseCase와 같은 생소한 단어가 나와도 대응할 수 있는 얕은 지식이 생겼다. 또한, 다음 서비스를 개발 할 때 위 처럼 외부와 통신하는 서비스의 변경을 고려한 설계를 하게 된다면, 헥사고날 아키텍쳐를 도입하는 것을 고려해 볼 수 있을 것 같다.
회사에서 JPQL을 통해 테이블 조인 및 검색 조건을 추가하는 쿼리를 작성하고 있었는데, 쿼리 성능 개선을 위하여 inlineView(from 절 subquery)를 작성해야 할 필요가 있었다.
많은 게시글에서 JPA에서 inlineView를 사용하지 못한다는 글을 봐서, 사용할 수 있는 다양한 샘플과 함께 회사 코드에서는 사용이 어려웠던 이유, Spring Data JPA 레포지토리에 이슈를 생성한 것 까지 모두 작성해본다.
JPA에서 inlineView, 사용가능한가?
사용가능하다. 이전에 작성한 글에서 이미 말했듯이, Hibernate 6.1 버전부터 inlineView가 사용가능 하다.
다만, 다양한 케이스를 테스트 하면서 알게 된 점은 데이터를 Entity, Interface Projection, Class Projection, List 형식 모두 상관없이 쿼리를 작성할 수 있지만, PageRequest와 함께 inlineView 쿼리를 작성하게 되면 JPA가 제공하는 count 쿼리만으로는 오류가 발생한다.
이 부분에 대해서는 Spring-Data-JPA 레포지토리에 이슈를 작성하여 문제가 맞는것인지, 해결 가능한 문제인지를 천천히 살펴 본 후 공유할 생각이다.
라이브러리를 유지보수 하시는 개발자께서는 이를 countQuery를 직접 작성하는 방법으로 문제를 해결하시길 권유하셨고, 이슈는 closed 상태가 되었다. 아마도 이 부분에 대해서 따로 지원하실 계획은 없는것으로 보인다.
[Spring JPA][Interface Projection] inline subquery with join - 가능
[Spring JPA][Class Projection] inline subquery with join - 가능
[Spring JPA][Interface Projection] multiple Join inline subquery with join - 가능
[Spring JPA][Interface Projection] multiple Join inline subquery with join and param - 가능
[Spring JPA][Interface Projection] page request without subquery - 가능
[Spring JPA][Interface Projection] page request without join - countQuery 추가 작성 필요
샘플 쿼리를 디버깅하면서 page타입으로 데이터를 수신할 때에만 Spring-Data-JPA의 AbstractJpaQuery 클래스의 createCountQuery에서 호출이 실패하고 오류 로그가 발생하는 것을 알 수 있었다.
아래는 호출에 실패한 count Query와 오류 로그이다.
SELECT count(T) FROM (SELECT T2.id as id, T2.name as name, T2.address as address FROM Member T2 ) T
org.hibernate.query.SemanticException: The derived SqmFrom[id, name, address] can not be used in a context where the expression needs to be expanded to identifying parts, because a derived model part does not have identifying parts. Replace uses of the root with paths instead e.g. `derivedRoot.get("alias1")` or `derivedRoot.alias1`
생성한 카운트 쿼리를 실제로 실행해봐도 정상적으로 동작하지 않는것을 알 수 있었는데, 위의 카운트 쿼리에서 InlineView 쿼리까지는 정상적으로 동작하지만 결과 테이블을 T라는 alias로 접근 가능하도록 했고 이를 바깥 쪽 SELECT 할 때 alias 테이블 이름만 사용했기 때문에 문제가 발생하는 것으로 보인다. 이를 T.id 처럼 alias와 함께 필드 이름을 적용하면 정상적으로 카운트 쿼리가 동작한다.
마무리
Spring-Data-JPA에 기여하는 것은 실패했다. 내 샘플 코드와 함께 문제를 찾고, 이를 통해 비슷한 문제를 겪었던 사람들에게 도움이 되길 바랬는데.. (Spring 기여자가 되고 싶은 마음이 제일 크긴하다) 아쉽지만 다음 기회를 노려야겠다 ㅎㅎ
결국에는 countQuery를 직접 입력하여 inlineView 쿼리문을 작성할 수 있었고 이를 통해 기존 쿼리 응답의 경우822.2ms, 수정된 쿼리의 경우 489.9ms 로 67.83%의 성능 개선을 얻을 수 있었다
회사에서 쿼리작성도중 From절 Subquery가 필요한 상황이 있었는데, 서비스가 Spring Data JPA를 사용하고 있었는데, 아직 자료가 많이 없는 상황이라 도움이 되기를 바라며 쿼리를 작성한 경험을 공유하고자 글을 쓴다.
JPA에서의 From절 Subquery 사용가능 여부 확인
JPA에서 From절 Subquery로 많은 검색을 해봤지만, 쓸만한 내용이 없었고 검색 결과에 가장 많이 보이는 내용은 JPA의 한계라는 내용이었다. 많은 글에서 JPA는 From절 Subquery를 지원하지 않는다는 내용을 볼 수 있었고, 그 중 Hibernate 6.1 버전에서 Subquery에 관한 지원이 추가되었다는 사실을 알게 되었다.
이 사실을 통해 hibernate 문서를 뒤졌고, from절에서 subquery를 사용하는 예제를 찾을 수 있었다.
하지만, 현재 Spring Data JPA 버전에서 6.1버전 이상의 Hibernate를 사용했는지 여부를 확인해야 했기에, 프로젝트 내부에서 버전 정보를 확인했다.
보시다시피 Hibernate6.4.1 버전을 사용하고 있었기에, 충분히 JPA로 쿼리를 생성할 수 있겠다는 결론을 내렸고, From절 Subquery를 만들어 보기로 했다.
From 절 Subquery 작성
테스트를 위해 기존에 JPA 학습을 위해 생성한 레포지토리 내에서 몇가지를 수정하여 테스트를 시작했다. 파일 구성은 아래에 소개한다.
테스트 파일을 작성 할 수도 있겠지만, 있었던 controller를 수정하는 것이 더 빠를것 같아서 Controller를 아래처럼 수정했다.
package com.hyeonwoo.spring.jpa.springjpa;
import com.hyeonwoo.spring.jpa.springjpa.domain.Address;
import com.hyeonwoo.spring.jpa.springjpa.domain.Member;
import com.hyeonwoo.spring.jpa.springjpa.service.MemberService;
import lombok.RequiredArgsConstructor;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.GetMapping;
import java.util.ArrayList;
@Controller
@RequiredArgsConstructor
public class HelloController {
private final MemberService memberService;
@GetMapping("test")
public void test(Model model) {
memberService.testSpringMember();
}
@GetMapping("insert")
public void insert() {
Member a = new Member(1L,"박현우", new Address("Seoul", "Main Street", "12345"));
Member b = new Member(2L,"차은우", new Address("Seoul", "Main Street", "12345"));
Member c = new Member(3L,"장원영", new Address("Seoul", "Main Street", "12345"));
Member d = new Member(4L,"카리나", new Address("Seoul", "Main Street", "12345"));
Member e = new Member(5L,"홍윤기", new Address("Seoul", "Main Street", "12345"));
memberService.insertTestDataSet(a);
memberService.insertTestDataSet(b);
memberService.insertTestDataSet(c);
memberService.insertTestDataSet(d);
memberService.insertTestDataSet(e);
}
}
아래는 Service 클래스이다.
Service 클래스에서는 Spring Data JPA를 통해 쿼리를 생성하는 방법과 Entity Manager를 직접 다루는 방법 두가지를 시도해보았다.
package com.hyeonwoo.spring.jpa.springjpa.service;
import com.hyeonwoo.spring.jpa.springjpa.domain.Address;
import com.hyeonwoo.spring.jpa.springjpa.domain.Member;
import com.hyeonwoo.spring.jpa.springjpa.repository.MemberRepository;
import com.hyeonwoo.spring.jpa.springjpa.repository.SpringMemberRepository;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.util.ArrayList;
import java.util.List;
@Slf4j
@Service
@Transactional(readOnly = true)
@RequiredArgsConstructor
public class MemberService {
private final MemberRepository memberRepository;
private final SpringMemberRepository springMemberRepository;
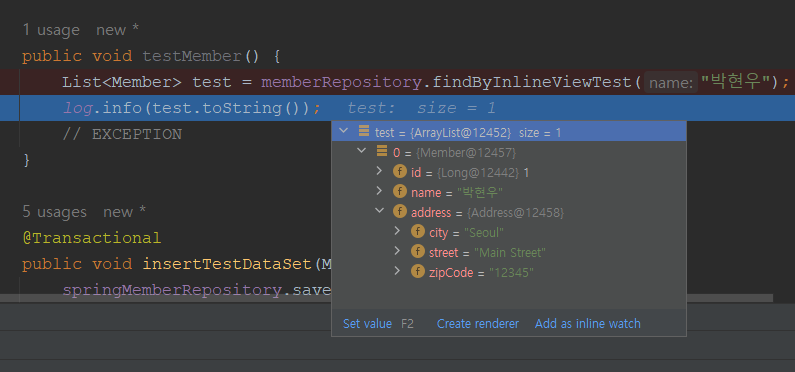
public void testSpringMember() {
List<Member> test = springMemberRepository.findByInlineViewTest("박현우");
log.info(test.toString());
// EXCEPTION
}
public void testMember() {
List<Member> test = memberRepository.findByInlineViewTest("박현우");
log.info(test.toString());
// EXCEPTION
}
@Transactional
public void insertTestDataSet(Member a) {
springMemberRepository.save(a);
}
}
아래는 Spring Data JPA를 통해 서브쿼리를 사용해보는 Repository 예제 코드이다.
Select 조건에 new Member라는 생성자를 통해 데이터를 삽입했는데, 생성자를 사용하지 않을 시 오류가 발생하여 아래의 StackOverflow 포스팅을 참고했다.
package com.hyeonwoo.spring.jpa.springjpa.repository;
import com.hyeonwoo.spring.jpa.springjpa.domain.Member;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.query.Param;
import java.util.List;
public interface SpringMemberRepository extends JpaRepository<Member, Long> {
@Query("SELECT new Member(T.id as id,T.name as name,T.address as address) FROM (SELECT T2.id as id,T2.name as name,T2.address as address FROM Member T2 WHERE T2.id = 1) T")
List<Member> findByInlineViewTest(@Param("name") String name);
}
EntityManager를 사용하여 쿼리를 생성한 예제이다.
package com.hyeonwoo.spring.jpa.springjpa.repository;
import com.hyeonwoo.spring.jpa.springjpa.domain.Member;
import jakarta.persistence.EntityManager;
import lombok.RequiredArgsConstructor;
import org.springframework.stereotype.Repository;
import java.util.List;
@Repository
@RequiredArgsConstructor
public class MemberRepository {
private final EntityManager em;
public List<Member> findByInlineViewTest(String name) {
return em.createQuery("SELECT T.id, T.name, T.address FROM ( SELECT T2.id as id,T2.name as name,T2.address as address FROM Member T2 WHERE T2.id = 1) T WHERE T.name = :name", Member.class)
.setParameter("name", name)
.getResultList();
}
}
마지막으로 Entity 클래스이다. 특별한 내용은 없다.
package com.hyeonwoo.spring.jpa.springjpa.domain;
import jakarta.persistence.*;
import lombok.*;
import java.util.ArrayList;
import java.util.List;
@Entity
@Getter @Setter
@RequiredArgsConstructor
@AllArgsConstructor
public class Member {
@Id @GeneratedValue
@Column(name = "member_id")
private Long id;
private String name;
@Embedded
private Address address;
}
package com.hyeonwoo.spring.jpa.springjpa.domain;
import jakarta.persistence.Embeddable;
import lombok.Getter;
@Embeddable
@Getter
public class Address { // 값 타입은 변경 불가능하게 설계해야 한다.
private String city;
private String street;
private String zipCode;
protected Address(){} // 임베디드 타입은 자바 기본 생성자를 public 또는 protected로 설정해야 한다.
// Setter를 사용하지 않고 생성자에서 값을 모두 초기화 해서 변경 불가능한 클래스로 제공
public Address(String city, String street, String zipCode) {
this.city = city;
this.street = street;
this.zipCode = zipCode;
}
}
위처럼 파일 세팅 후 H2 데이터베이스에 데이터를 임시로 삽입하는 API를 호출했고, 이후 서브쿼리를 통해 데이터를 조회하는 부분에서 디버깅을 통해 데이터가 잘 들어오는지 확인할 수 있었다.
알게된 점
hibernate 6.1버전 이상에서는 JPA를 통해 From 절 Subquery SQL을 작성 할 수 있다.
Subquery 작성 시 alias를 작성하지 않으면 이름을 찾지 못하는 오류가 있는 것 같다. 예제에서도 alias가 필수적으로 붙어있는 이유로 보인다.
Entity 타입으로 데이터를 조회할 수 있었지만, class Projection을 통해서는 데이터를 수신하는데 실패하고 있다. 이 부분은 좀 더 확인해보고, 공유할 만한 내용이 있다면 공유할 생각이다.
개인 프로젝트 기획 중 Google Colab을 통해 생성한 모델에서 API를 통해 프롬프트를 전달하고, 해당 정보로 API를 호출하는 서비스를 만들기 위해서 Stable Diffusion WebUI에서 API 호출을 확인해야 했다. 이를 어떻게 해결했는지 공유하고자 글을 작성한다.
API 호출하기
API를 호출하기 위해서는 검색해보니 python 코드를 수정해야 한다는 내용을 몇가지 찾을 수 있었는데, 별도의 코드 수정없이 간단하게 API를 호출할 수 있는 주소를 알아낼 수 있었다. 바로 Stable Diffusion WebUI 하단에 API를 클릭하면 사용가능한 API 목록을 swagger를 통해 알 수 있다.
Swagger 페이지를 통해 내가 호출하고자 하는 API를 확인했고, 나의 경우 txt2img API를 호출하기 위한 정보를 찾아봤다.
하지만 많은 파라미터가 있어 내가 설정했던 방법을 간단히 살펴보자.
{
"prompt": "sparkling eyes, giving a playful, resembling a fantasy or magical theme, The character has a joyful and friendly expression, with a child-friendly design that uses soft curves and bright, smooth textures", // 프롬프트
"negative_prompt": "Avoid dark or muted colors, no sharp or aggressive features, no realistic textures, avoid mature themes, no complex backgrounds, no human-like proportions, no gothic, horror, or creepy aesthetics, avoid exaggerated shadows or dramatic lighting, and no realistic animal features", // Negative 프롬프트
"styles": [
""
],
"seed": -1, // 시드 (-1 : 랜덤)
"subseed": -1,
"subseed_strength": 0,
"seed_resize_from_h": -1,
"seed_resize_from_w": -1,
"sampler_name": "DPM++ 2M", // 샘플러 name
"scheduler": "",
"batch_size": 1,
"n_iter": 1,
"steps": 20, // Sampling Steps
"cfg_scale": 7,
"width": 512,
"height": 512,
"restore_faces": false, // default true여서 false로 변경
"tiling": false, // default true여서 false로 변경
"do_not_save_samples": false,
"do_not_save_grid": false,
"eta": 0,
"denoising_strength": 0,
"s_min_uncond": 0,
"s_churn": 0,
"s_tmax": 0,
"s_tmin": 0,
"s_noise": 0,
"override_settings": {
"sd_model_checkpoint": "Hyeonwoo/Hyeonwoo_5200.safetensors [d85b89c9ef]" // 사용할 model check point
},
"override_settings_restore_afterwards": true,
"refiner_checkpoint": "",
"refiner_switch_at": 0,
"disable_extra_networks": false,
"firstpass_image": "",
"comments": {},
"enable_hr": false,
"firstphase_width": 0,
"firstphase_height": 0,
"hr_scale": 2,
"hr_upscaler": "string",
"hr_second_pass_steps": 0,
"hr_resize_x": 0,
"hr_resize_y": 0,
"hr_checkpoint_name": "",
"hr_sampler_name": "",
"hr_scheduler": "",
"hr_prompt": "",
"hr_negative_prompt": "",
"force_task_id": "",
"sampler_index": "Euler",
"script_name": "",
"script_args": [],
"send_images": true,
"save_images": false,
"alwayson_scripts": {},
"infotext": ""
}
위와 같이 설정 후 Stable Diffusion Web UI를 통해 생성한 데이터와 거의 비슷한 결과값을 얻을 수 있었다.
응답값은 image base64 인코딩 데이터와 생성에 사용된 메타데이터들이 응답으로 왔었고, 이미지 데이터는 base64 디코딩 사이트를 통해 확인할 수 있었다.
Stable Diffusion Web UI를 사용할 때, DreamBooth extension이 정상적으로 설치된 경우 다음과 같이 Train 카테고리 옆에 표시 되어야 한다.
하지만 어느날부터 DreamBooth 카테고리가 사라져서 보였고, Stable Diffusion Web UI 실행 시 아래의 로그를 얻을 수 있었다.
*** Error executing callback app_started_callback for /content/gdrive/MyDrive/sd/stable-diffusion-webui/extensions/sd_dreambooth_extension/scripts/api.py
Traceback (most recent call last):
File "/content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/script_callbacks.py", line 256, in app_started_callback
c.callback(demo, app)
File "/content/gdrive/MyDrive/sd/stable-diffusion-webui/extensions/sd_dreambooth_extension/scripts/api.py", line 534, in dreambooth_api
model_cfg: DreamboothConfig = Body(description="The config to save"),
NameError: name 'DreamboothConfig' is not defined
위의 내용으로 chatGPT에게 물어본 결과, DreamBooth를 실행하기 위한 의존성의 문제처럼 보인다고 한다.
또한, 아래의 명령어를 알려주었다.
!pip install -r /path/to/requirements.txt
난 현재 Google Colab에서 Stable Diffusion을 사용하고 있었기에, sd/stable-diffusion-webui/extensions/sd_dreambooth_extension/requirements.txt 경로에서 해당 파일을 얻을 수 있었다.
requirements.txt 파일 선택 후 경로 복사를 해준다.
이후 임의의 위치에 코드 삽입 후 경로를 붙여넣고 실행시켜준다.
실행이 완료되었다면 Stable Diffusion Web UI 재시작 해주면 정상적으로 표시된다.
글에서 짧게 소개했지만, Github Foundations Github에 대한 기초적인 지식을 검증하는 자격증을 따기 위해 며칠간 공부 했었고, 후기를 남기고자 글을 쓴다.
왜 Github Foundations?
국내에서 Github Foundations를 가진 사람을 아직 본적이 없다. 1등으로 해보고 정보를 공유하고 싶었다.
Git 이라는걸 참 좋아하고 잘 사용한다고 생각해서, 스스로 증명하고자?
자격증 비용이 꽤나 저렴했다. 99$로 표시되지만 실제 결제를 하니 의문의 바우처가 적용되어 45$ + 4.5$ 세금으로 총 49.5$에 자격증 시험을 볼 수 있었다.
좋았던 점
Github Foundations를 공부하면서 또다른 Open Source Contributor와의 접점이 생겼다.
Github의 다양한 기능들을 구경할 수 있었다. (submodule, issue form)
아직 Github Foundations를 가진사람을 못봐서 약간 멋이난다.
안좋았던 점
결제를 하면서 알았는데, 해당 시험은 non-protctored exam 이다. 컨닝해도 된다..
번역 기능이 제공되지 않아서 영어에 익숙하지 않으면 굉장히 어렵다..
ghcertified와 같은 덤프 사이트의 문제로는 조금 버겁다. 확실히 자료가 부족한만큼 시험 난이도가 어렵게 느껴졌다.
결제 할 때에도 한국 전화번호가 사용 불가능해서, 전화번호 인증 없이 바로 다음 섹션으로 넘어 갔었다. 전체적으로 영어권이 아니라면 불친절하게 느껴질 수 있다.
그래서, 추천하나?
나는 굳이 github foundations 자격증을 추천하지 않겠다. 감독관이 없는 시험은 크게 메리트가 있다고 느껴지진 않는다. 또한, Github는 git을 주요 기술로 사용하는 다양한 플랫폼 중 하나이다. (Github, Gitlab, Bitbucket..) 따라서 플랫폼마다 조금씩의 차이점이 있고, 회사에따라 각각 다른 플랫폼을 사용한다. 그래서 크게 인정받을 수 있는 자격증인가..는 잘 모르겠다.
그래도 Github Foundations를 통해 얻는점도 있었고, 블로그에 글을 쓸 수 있으니 좋다~
AWS에서 주최하는 Migrate, Modernize, Build 관련 강연에 대해 메일로 정보가 와서, 고민없이 바로 접수했다.
세션 선정
다양한 세션중에서 내게 도움이 될 만한 것들을 5개 선택해봤다. (오전 세션으로 선택했던건 사라져버림?)
데이터 환경의 현대화: 실시간 데이터를 위한 인메모리 캐싱과 NoSQL 활용방법
NoSQL을 사용해본적은 있지만, 더 잘 사용하려면 어떻게 해야할까? 라는 마음으로 신청했다.
서비스 성능 개선을 위한 데이터베이스 및 애플리케이션 현대화 전략: GenAI 활용법
이 세션은 현재 내가 속한 팀에서 데이터베이스 마이그레이션 관련 문제를 겪고 있으신 분이 계셔서, 도움이 될 만한 내용을 공유드리고 싶어 신청했다.
Amazon Q Developer를 활용한 개발자 생산성 향상의 첫걸음
처음 들어보는 서비스 였는데, 생성형 AI를 개발자 생산성 향상 서비스라고 하여 아마 Copilot, GPT 같은 서비스 일 것이라 생각했고, 차이점이 궁금해 신청했다.
미디어 DevOps 혁신을 이끄는 IaC 기반 Amazon EKS 업그레이드
IaC, EKS 관련 이해도를 높이고 싶어 신청했으나.. 이해가 어려워 스킵했다.
제조업의 미래를 만드는 클라우드 혁신과 Platform Engineering 여정 - LG 그룹 사례
Platform Engineering 이란 키워드가 궁금하여 신청 했다.
후기
내 세션 리스트는 두가지로 나뉠 수 있을 것 같다.
AWS에서 개발한 서비스 소개 (1,2,3번 세션)
AWS 서비스를 실제 서비스 개발에 사용한 사례 (4,5번 세션)
첫번째로, AWS에서 개발한 서비스 소개의 경우 흥미로웠던 점은 AWS 서비스에서도 이제 생성형 AI를 적극 활용한 서비스들을 만나볼 수 있었다.
아마존 베드락의 경우 Chat GPT와 같은 대화형 AI를 통해 데이터베이스 이관 및 마이그레이션에 도움을 주는 데모 영상을 봤는데, GPT와 사용하는것에 있어서 다른점은 크게 못 느낀 것 같다. 하지만, AWS에서 개발했다는 점에서 AWS 서비스들과의 호환성은 보다 뛰어날 것이라고 생각한다.
Amazon Q Developer의 경우 Copilot 처럼 IDE와 통합 및 아마존 콘솔에서 사용가능 했는데, 소프트웨어 개발 전반적으로 관여를 하고 도움을 준다는 점에서 인상이 깊었고, 아마존 콘솔에서 직접 람다 함수 작성 시 오류 발생에 대한 원인을 알려주고, 해결책까지 콘솔에서 안내해준다는 점이 인상깊었다. 이와 같은 서비스가 없었다면 구글링 했어야 할텐데..
두번째로, AWS 서비스를 실제 서비스 개발에 사용한 사례에서는 4번 세션의 경우 IaC, EKS 관련 경험이 없던 내가 이해할 수 있는 레벨은 아니었다. 따라서 5번 세션에 대한 후기만을 남긴다.
먼저 Platform Engineering이라는 새로운 개념에 대해서 알 수 있었고, LG Innotek의 사례를 통해 이러한 Platform Engineering을 통해 얻는 이점을 알 수 있었다.
궁극적으로 "프로젝트의 템플릿화를 통해 프로젝트 초기 생산성 향상 및 운영 효율성 증가" 라는 키워드가 Platform Engineering 을 표현할 수 있다고 생각한다.
처음에 소개했던 공통 컴포넌트 개발, 표준 프레임워크 지정, 템플릿 코드, 쿠버네티스 표준 지정과 같은 표준을 지정하고 이렇게 만들어진 표준을 IDP (Internal Developer Platform)라는 내부 플랫폼을 통해 사내 개발자들이 템플릿을 선택하여 인프라 및 공통 코드까지 한번에 쉽게 구축할 수 있다는 점이 인상적이었다.
또한, 이러한 IDP 개발을 위한 Backstage 라는 자체 템플릿 개발에 활용할 수 잇는 오픈소스를 알 수 있는 계기가 되었다.
사실 SAA-C03를 공부하면서 불과 두달전까지 AWS 서비스들에 대해서 많이 공부한 것 같은데, 새로운 기능들이 빠르게 개발되고 있는것을 보니 개발업계는 정말 빠르게 변화하고 있다는걸 다시 한번 느낀다.
네트워크 상에서 일시적인 오류가 발생했을 때, 재시도 간격을 점진적으로 늘려가며 재시도를 수행하는 알고리즘.
주로 네트워크의 혼잡을 피하거나, 서버가 과부하 상태일 때 과도한 요청을 방지하기 위해 사용된다.
방법의 핵심은 "지수적으로" 대기시간을 늘리는 것
지수 백오프의 필요성
네트워크 통신 중 오류가 발생할 경우, 클라이언트는 보통 재시도를 통해 이를 해결하려고 한다. 하지만 모든 클라이언트가 동시에 재시도를 한다면, 서버는 한꺼번에 많은 요청을 처리해야 하므로 부하가 증가할 수 있다. 이러한 현상을 "재시도 폭주"라고 하며, 이를 방지하기 위해 지수 백오프를 사용한다.
하지만 이 방법도 한계가 있다. 어차피 동시에 요청이 몰린다면 똑같은 시간 간격으로 모든 재시도가 동일하게 몰릴 것이기 때문이다.
지연변이 (Jitter)
Jitter는 데이터 통신 용어로 사용할 때는 패킷 지연이 일정하지 않고, 수시로 변하면서 그 간격이 일정하지 않는 현상을 의미한다. Jitter 개념을 Retry에 이용하면 API를 요청하는 클라이언트 간의 동일한 재시도 시간 간격에 무작위성을 추가하여 서로 요청하는 시간대의 동시성?을 분산시킬 수 있다.
위 두 개념을 적용하면 지수로 증가하는 Backoff 시간에 일정 범위 안의 랜덤 대기 시간을 추가적으로 더하는 것으로 요청을 분산할 수 있다.